In this paper we introduce a programmatic approach to authoring of WWW documents. As the essence of the paper, we propose that WWW documents are written as functional programs. The main conclusion of the paper is that the programmatic approach is well-suited for authoring of complex WWW materials. At the more detailed level it is concluded that the flexibility of a Lisp programming language is a good basis for a programmatic WWW author. The paper describes the relations between programming and markup in the development process and in the source documents. It is illustrated how the Scheme-based software package LAML can be used to support a flexible programmatic authoring process. As a key idea, LAML mirrors every element in HTML as a Scheme function. On top of the mirror LAML offers a variety of document styles, tools, and environmental support.
Authoring of World Wide Web material involves construction of documents with XML or HTML markup as well as some amount of server and client side programming. This paper is about the application of programmatic means for authoring of relatively static WWW documents.
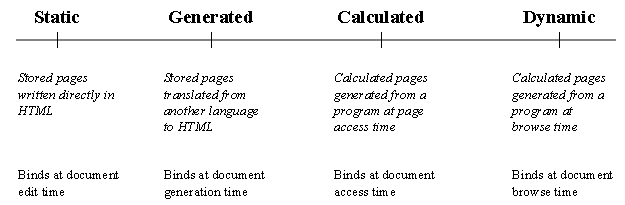
In order to achieve a more precise discussion of static and dynamic WWW documents we will distinguish between four classes of documents, and four different binding times. The four document classes and the related binding times are illustrated in figure 1. The binding time represents the execution time of the involved program (if any); The web page is frozen to a fixed appearance at document binding time. In the one extreme, static documents are written directly in HTML, and no program dynamics is involved at all. Such documents are bound at edit time. In the other extreme, a dynamic document is never really frozen, because program execution takes place in the browser at the time the document is being read. Calculated documents are frozen at the time the document is delivered by the WWW server. As such, they represent an important class of documents that are generated by programs running at the web server. Finally, generated documents are bound at an earlier point in time, for instance by application of a transformation program that generates fixed HTML markup from higher level markup (in an XML language or a similar language).
In this paper we will focus on generated pages. More specifically, we will deal with authoring of web documents using a programming language as the document source language. We reserve the term programmatic authoring for this endeavor. We will discuss the generation of HTML documents from a document source program, written in a programming language. Thus, we are concerned with the situation where WWW documents are written by use of a programming language instead of a markup language. This calls for a number of considerations of the interaction between the programming language and the underlying WWW technologies. This paper will present a possible solution to these challenges using a functional programming language as the foundation.
Given the idea of a document source program for the creation of static WWW pages, several kinds of processing of the document source program may be possible. However, the most prominent of these seems to be the one that translates the document source program to HTML. Therefore, in our work, the execution of the document source program derives an HTML file, or a set of such files.
The most novel idea in our work is indeed the use of a programming language as a document source language. As it will be discussed below, some programming paradigms and languages are better suited than others to support a programmatic authoring process. In our work we rely on the functional programming paradigm and Scheme [1] - a language in the Lisp family.
The development of most non-trivial WWW documents involves some degree of programming. Many web documents are calculated by a WWW server, as a response to form input from the user. Other web documents are generated by a tool, which in this context can be seen as a fixed program that creates the underlying HTML document from a higher level description. Yet other programs are used in dynamic documents at the client side (java applets, java script programs, and others). In our work we apply a programming language as an authoring language for static WWW pages. This approach to WWW authoring creates an ideal ground for an integration of WWW technologies and the necessary elements of programming.
As one of the main ideas, we mirror the HTML markup language in the programming language. This HTML mirror allows us to work exclusively in the programming language without use of mixed language documents (such as an HTML shell with embedded program fragments). The uniform use of a single linguistic framework - in our work, a programmatic framework - is more powerful than a mixed approach. Mixing markup and program fragments in a single document creates borderlines between two linguistic universes which cannot smoothly interact with each other. In some server page frameworks it is difficult to form abstractions that involve both pieces of markup and program fragments [12]. In addition, it becomes more difficult to provide good tool support of a document, which involves several languages. At the aesthetic level, the mixing of two languages in a single document gives a confusing impression, and it almost certainly eliminates any rest of elegance from the source document. In comparison between a markup language and a programming language, the latter is the one holding the dynamic power. Thus, we go for an inclusion of the weak language in strong one. The other possibility (extending the markup language with programming capabilities) seems to be less attractive. We will return to this issue in section 4.3 of this paper.
In this paper we will argue that authoring of complex WWW materials involves almost the same challenges - problems and solutions - as development of non-trivial software. This includes, for instance, general mastering of complexity, avoidance of redundancy, abstraction to eliminate distracting details, modularization, and separation of concerns. Using a programmatic approach to WWW authoring makes it natural and straightforward to apply a variety of programming techniques on WWW documents. The power of programmed solutions is available at any time in the document development work, and at any place in the document.
We are well aware that a programmatic approach to WWW authoring - brought to the extreme - will have a hard time to be successful for WWW authoring in the large. We believe, however, that there exists a variety of niches in which the techniques proposed in this paper can play a significant role, both with respect to productivity and quality of the authored documents and web sites. Our own [14] and other's [23] use of the LAML software packages, and use of similar packages [8] give clear indications in this direction.
In section 2 we discuss the general benefits of a programmatic WWW authoring approach. In section 3 the approach is illustrated by means of a concrete example. This gives a foundation for section 4 in which we discuss programming paradigm issues and programming language issues related to WWW authoring. In section 5 we describe LAML in some details. Related work will be described in section 6.
Basically, programming is about automating a solution to a given problem. A programmed solution usually takes responsibility for the execution of a large number of steps - or evaluation of a complex expression with a large number of subexpressions - which otherwise should be done manually.
Equally important, programming is about abstraction. It is difficult and error prone to deal with a great number of primitive steps, or an expression with a large number of operands. The abstraction mechanisms supported by most programming languages allow the programmer to formulate the program at a higher level. Some of the original steps or operands are encapsulated, named, and generalized by means of parameters such that the resulting procedure call or function call involves fewer details.
It is our hypothesis that WWW authoring will benefit from the programmatic techniques mentioned above. Automation in the context of WWW authoring can be brought in by a variety of different means. Typically, however, the author applies a tool on a document in order to check if it fulfills some given properties, or in order to convert it to another format. If, however, the source of the WWW document is a program, automated solutions can be integrated more smoothly. As part of the document we can apply a piece of program (a procedure) that carries out the needed calculation (check or transformation). If such a procedure does not already exist, we have a chance to write it ourselves. If the procedure is particular to the current document, it can just stay in there. If we produce a solution to a problem, which is likely to reappear in other documents, we can make the procedure available in a library for more general use.
Abstractions created and applied by the WWW author is a key idea in XML, as well as a much wanted (but missing) concept in HTML. XML offers no computational dynamics, and as such it depends on external mechanisms for the implementation of the abstractions. Using the programmatic approach to WWW authoring, the existing abstraction mechanisms of the programming language can be used to lift the document source language in the needed direction. In addition, the abstractions can be implemented in the programming language, as functions or classes. Using a well-proven and general purpose programming language for such purposes is probably better than relying on new, special purpose languages.
The automation of routine tasks and the use of document abstractions will appear both the in small and in the large. To be concrete, we will mention the following examples of small scale automation, which we use regularly in our programmatic WWW documents:
Similarly, we use ad hoc abstractions such as
tr and td HTML elements.For the purpose of writing the XHTML version of this paper we developed a few ad hoc abstractions that helped us to create the paper from a LAML source. Most notably we automated cross references to figures and sections, and we made use of the LAML bibtex tool to produce the bibliography of the paper. The set of ad hoc abstractions may in the future be refined to a new XML-in-LAML document style.
Used in a larger scale, automation of routine tasks will lead to creation of major and generally applicable tools. As examples of such tools, the LAML software package includes parsing and pretty printing tools for HTML and XML, transformation tools between XML and LAML, bookmark management tools, a bibtex tool based on a Lisp representation of bibtex entries, interface comment extraction tools for Scheme, and a spell support tool. Abstraction can lead to the formulation of languages that form vocabularies in well defined domains. In section 3 we will discuss an example of such a language - a language for educational quiz purposes. The LAML package support languages (document styles) for lecture note material [16], course home pages [14], software manuals, scientific papers, and others.
Although beneficial, as argued above, programmatic problem solving is not in widespread use in the domain of static web authoring. Rather, interactive approaches using special purpose tools with almost fixed functionalities dominate among WWW authors. The underlying problem is that only a minority of the WWW authors feel comfortable writing programs. In fact, the programming tasks and the authoring/design tasks are often separated in a WWW development process, to facilitate the different competences of the developers. This is, of course, a serious concern. We realize that we provide tools only for a minority of WWW authors. The typical author using the programmatic approach is minded for programmatic problem solving. He or she, in addition, feels a need for more power than typically provided by the interactive tools, such as SGML/XML/HTML structure editors. As such, we can think of programmatic authors as power authors who want to use tools and techniques that alleviate a variety of problems caused by document complexity (many nodes and links, material in several versions, etc).
Before we continue the discussion at the general level we wish to give the reader a concrete feeling for the programmatic approach to WWW authoring that we use in our work. Thus, in this section we will illustrate the LAML approach to WWW authoring, which is based on the functional language Scheme from the Lisp family of programming languages together with a number of libraries. In subsequent sections of the paper we will broaden the discussion both with respect to WWW authoring using functional programming languages, and with respect to the LAML fundamentals.
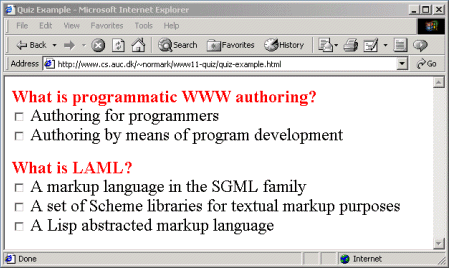
Let us assume that we want to develop a multiple-choice quiz service on the WWW. Figure 2 shows an example of a page with a couple of questions and possible answers. The user of the quiz service is supposed to select the right answers; Upon submission, the user will receive feedback, explaining why the checked answers are correct, or why they are incorrect. The quiz page as such is considered as a generated document (although it could as well be made as a calculated document, using the classification of figure 1.) The answer page will be calculated or dynamic, because it is created by the WWW server or in the client browser, based on the choices made by the quiz user.
From an authoring point of view it is important that the quiz can be formulated at an appropriate level of abstraction. We therefore form a tiny language which allows us to describe a quiz in terms of questions and answers. Figure 3 shows a sample quiz description, corresponding to the quiz shown in figure 2. A quiz consists of a number of quiz entries, each of which consists of a single question and a number of possible answers. Each answer has a formulation of the answer, a measure of correctness, and an answer clarification. The measure of correctness is a number between 0 and 100, where 0 means 'wrong', 100 means 'correct'. Numbers in between represent partial correctness. The answer clarification is a description that explains why a given answer is wrong, partially correct, or correct.
(load (string-append laml-dir "laml.scm"))
(laml-style "demo-quiz")
(quiz
(list
(quiz-entry
(question-formulation "What is programmatic WWW authoring?")
(answers
(list
(answer
(answer-formulation "Authoring for programmers")
(answer-correctness 0)
(answer-clarification
"Using programmatic authoring the document source
is a program"))
(answer
(answer-formulation
"Authoring by means of program development")
(answer-correctness 100)
(answer-clarification
"The source of each WWW document is a program")))))
(quiz-entry
(question-formulation "What is LAML?")
(answers
(list
(answer
(answer-formulation "A markup language in the SGML family")
(answer-correctness 0)
(answer-clarification
"LAML is a markup language using Lisp syntax"))
(answer
(answer-formulation
"A set of Scheme libraries for textual markup purposes")
(answer-correctness 90)
(answer-clarification
"In addition there are various tools in the LAML package"))
(answer
(answer-formulation "A Lisp abstracted markup language")
(answer-correctness 100)
(answer-clarification
"The name covers document styles, libraries and tools")))))
)
) |
A quiz description, like the one shown in figure 3, is an expression in the functional programming language Scheme. The Scheme quiz expression is similar to an XML fragment which uses a number of different quiz elements (with XML tags). When the top level quiz expression is evaluated by the Scheme interpreter a structure is returned, which can be rendered to present the quiz. In most situations it is convenient to have the Scheme interpreter return an HTML document equivalent to the LAML expression. After all, one of the most typical actions on our documents is to present them in a browser. In general, however, the quiz expression can be seen as a declaration of some basic quiz facts; The quiz expression can be evaluated, traversed, transformed, or queried in different ways, using special purpose interpreters. In any case, such processing is relatively easy to deal with, because document parsing can be handled by the generic Scheme reader, and because subsequent processing can be done using Scheme functions.
In Scheme it is straightforward to program functions that transform the quiz expression in figure 3 to HTML. We make use of the LAML mirror of HTML, in which each HTML element is represented as a function in Scheme. The mirror will be discussed in more details in section 5. The functions involved in the transformation are shown in appendix A.
We will now illustrate the power and flexibility we obtain by representing the quiz as an expression
in a functional programming language. Let us assume that we only want to deal with the subset of
questions that exclusively contains correct or wrong answers.
In other words, we wish to disregard the questions to which we present partially
correct answers. Relative to the example in figure 3 this eliminates the last
question. The change of the quiz can be realized by a simple filtering of the quiz entries, as sketched in figure
4. The filter function is a commonly used so-called higher-order function which is well-known
from functional programming languages. An application of filter returns the elements of a list that
satisfy a given predicate. The predicate black-or-white-quiz-entry? is found as part of
the program definitions in appendix A.
(quiz
(filter
black-or-white-quiz-entry?
(list
(quiz-entry
...)
(quiz-entry
...)
)
)
) |
In a recent development we have introduced a surface syntax which we call XML-in-LAML.
Using this syntax there is trivial correspondence between the syntax of an XML document
and a LAML document.
Relative to the example in figure 3, some of the document clauses
(such as answer-correctness clauses) would be better represented as attributes.
The XML-in-LAML syntax is similar in style to the HTML mirror functions which we discuss
in section 5.
When we are going to complete the Quiz service we are likely to write a WWW server program (such as a CGI program) which checks the answers. (In this example, we could as an alternative, carry out the check at the client side - typically using a Java Script program, but we will not deal with this alternative in the present paper). As the feedback from the WWW server, we chose to return the original quiz page with embedded qualitative evaluation of the answers. Using this approach, it is possible to submit the quiz once more, and hereby explore the quiz in additional details. In this context it is worth noticing that the functional paradigm fits nice as well. The server side program receives as input the choices made by the quiz user, and as result it returns a specialized version of the quiz page. Many simple server side solutions work in this way.
By using a programmatic authoring approach, as illustrated in figure 3 and 4, the gap between the quiz WWW page, as written by the quiz author, and the server side checking program becomes smaller than in other kinds of solutions. Both parts of the system are programs in the same programming language, and the server side checking program can use some of the same functions as used by the quiz author, cf. appendix A.
Let us briefly discuss how the quiz example could be developed using a more conventional approach.
It would not be attractive to author the quiz interface in pure HTML (using either an HTML editor or
a text editor). The author would typically (but due to CSS [2] not necessarily) commit himself or
herself to a particular presentation of the quiz which is only of minor importance to the quiz
apparatus as such. Some of the functions in appendix A, such as
present-quiz-entry, represent style sheet information. This could involve CSS expressions,
but this is not the case in our setup, because the documentation source already is
separated from layout concerns. Thus, the programmatic authoring approach can be used to obtain many
of the advantages known from the application of external and separate style sheets.
Many developers would probably implement a pure server side solution to the problem, taking the quiz input from some data structure or database, and generating HTML output via use of PHP, ASP, JSP, or similar frameworks. This, however, involves mixed HTML work and programming in a conventional imperative style, which we find is less attractive than the functional style illustrated above. We will discuss this issue in more details in the following section of this paper.
As yet another alternative, some authors would probably be tempted to author the quiz in XML. This will involve the construction of a DTD or an XML Schema (corresponding to a context free grammar of the quiz language), quiz XML authoring quite similar to the quiz shown in figure 3, and programming of transformers from XML to HTML (using XSL, for instance). Finally, the server side checking must be done, in yet another framework (such as PHP, ASP, or Java). As can seen, this solution involves several, special-purpose technologies, whereas the Scheme/LAML approach only involves a single framework. We see this kind of simplicity as an important advantage of the programmatic authoring approach described in this paper.
In this section we will compare the imperative and functional paradigms with respect to programmatic WWW authoring. This is relevant because imperative programming is the main paradigm of very many programmers. As a subsequent discussion we will deal with some more detailed properties of programming languages, which are important when we use these languages for WWW authoring purposes.
We claim that the imperative programming paradigm does not fit well with the needs of the WWW author. As a related observation, we see similar problems at the WWW server side. The argumentation will be rooted in the example shown in figure 5, which is similar to the example in figure 3.
procedure print-quiz;
begin
print-quiz-entry-start("What is programmatic WWW authoring?");
print-answer("Authoring for programmers", 0,
"Using programmatic authoring the document source
is a program");
print-answer("Authoring by means of program development",
100, "The source of each WWW document is program");
print-quiz-entry-end;
print-quiz-entry-start("What is LAML?");
print-answer("A markup language in the SGML family", 0,
"LAML is a markup language using Lisp syntax");
print-answer("A set of Scheme libraries for textual markup purposes",
90,
"In addition there are various tools in the LAML package");
print-answer("A Lisp abstracted markup language", 100,
"The name covers document styles, libraries and tools");
print-quiz-entry-end;
end;
begin
print-quiz;
end. |
Each of the procedures in the program shown in figure 5 prints text,
say to standard output. The procedure called print-answer corresponds to the answer function of figure 3. We chose to split the function quiz-entry into print-quiz-entry-start and print-quiz-entry-end. It would be difficult to handle a separate
print-quiz-entry procedure because it would need a large amount of 'flat' parameters in the general
case (all possible answers, percent numbers, and clarifications to a question).
The single most important thing to notice about the imperative solution is that procedure calls do not nest in the same way as function calls. The reason is that procedure calls are commands to which we can pass various kinds of parameters, none of which can be commands themselves. As a contrast, function calls are expressions to which we can pass other function calls as actual parameters. The function calls in figure 3 nest in a way which is similar to the nesting of element applications in an HTML or XML document. This nesting of elements is difficult to mimic in an imperative solution. We could go for a mixed-paradigm solution in figure 5 (application of functions side by side with procedure calls), but this would only blur this discussion.
The comparison from above also holds when we deal with CGI-like programming at the server side. In an ASP or PHP program, which uses imperative programming techniques, we see the following pattern again and again:
print(start-tag-1, attributes-1);
print(contents-1)
print(start-tag-2, attributes-2);
print(contents-2);
print(end-tag-2);
print(end-tag-1)As a contrast, this corresponds to the Scheme function call
(tag-1 attributes-1 contents-1 (tag-2 attributes-2 contents-2))
in which an outer context (not shown here) is supposed to handle the necessary rendering and file output issues.
In this paper we go for a radical solution to the WWW authoring problem in which the source of a WWW document is a program that fulfills the rules of a programming language. This is not a problem for server side development which is generally accepted to be within the programmatic domain. The case is different with respect to more conventional, static WWW authoring of a set of interlinked WWW pages. The question is the following:
Can we in a reasonable way write a program which serves as the source of a set of interrelated WWW pages? The WWW author uses the programming language and environment as an authoring environment. When the program runs it generates the underlying WWW pages.
Programming languages with complicated syntactic rules are not good for this purpose. It would probably take an extraordinary enthusiastic C, C++, Pascal, or Java programmer to write a (non-server based) set of interrelated WWW pages directly in one of these programming languages.
Programming languages with more flexible syntax rules are better candidates. We have found that Scheme can be used with success, and we believe that other functional programming languages are candidates as well.
Next to the issue of a flexible syntactic composition of programs (and thus WWW documents) comes the question of type safety. Programming languages with static typing allow us to identify type errors before the program is executed. If we use a programming language with static typing for programmatic authoring we can ensure, as part of program compilation, that the resulting document is valid. However, the price for this safety can be relatively high in terms of rigid and limited composition and processing of programmatic documents. As a contrast, programming languages with dynamic typing deal with typed data objects at run time. Such languages cannot statically guaranty that the documents are valid, but they can provide for flexible document composition and processing, based for instance on generic list types, as known from Lisp. As we will see in section 5 of the paper, LAML supports dynamic document validation at the level of HTML (as an integrated part of the execution of the document source program.)
The discussion above easily boils down to the contrast between a theoretical approach and a more practical approach to programmatic authoring. Using the theoretical approach, the checking of documents becomes the main focus of the work. Using the practical approach, the flexible creation of a complex set of documents (a few of which may be non-valid or problematic) is the most important concern. As it appears from the discussion above, we adhere to the practical approach in our research and development work using LAML.
WWW authoring involves expressions in markup languages as a central element. If we use a programmatic approach we may end up using a mixture of programming language constructs and text with markup in a single document. Take as an example the case where all the HTML markup is located as strings in print commands, or where all program parts are located inside particular tags. This is aesthetically unpleasing, but even more important, it makes it difficult to use programmatic solutions (automations or abstraction) uniformly throughout the entire document.
We therefore find it important to come up with a solution which integrates the programmatic constructs with the markup expression. In the LAML system it has been our choice to embed the expressiveness of HTML in the programming language. We could also go in the other direction, namely to embed the programming language in the markup language. The Latte system [3] is a Scheme related example of this, cf. section 6. XSL [28] - the style sheet and transformation language for XML - is an example of an XML language of in the area of programming. As mentioned in the introduction, the XML language XEXPR [13] is another proposal in this direction. The rationale behind our solution is to use the most powerful language as a host for the less powerful language. It has been relatively straightforward to embed HTML/XML in Scheme, whereas the realization of Scheme as part of an XML language will require much more work.
It is also relevant to mention the role of program errors, either revealed at compile time or at run time. Due to the 'nature of programming' we have to deal with such anomalies in a programmatic authoring process. Notice, however, that some of these errors have natural counterparts in an authoring process which uses a markup language. Such errors are often first revealed at document validation time, or more typically at browse time via a surprising rendering of the document.
LAML [20 , 21 , 19] means Lisp Abstracted Markup Language. LAML consist of a number of libraries, tools, and document styles all of which can be loaded by most existing Scheme systems.
The foundation of LAML is the mirrors of HTML in Scheme. LAML supports mirrors of different variants of HTML, such as XHTML strict and HTML4.01 transitional. A mirror provides a Scheme function for each HTML element. By use of the mirror functions we eliminate literal HTML expressions from the document source program, but we still have the full expressiveness of HTML available. A mirror is produced by parsing one of the HTML document type definitions (DTDs) followed by the necessary information retrieval and synthesis of the Scheme functions. The HTML clause
<tag a1="v1" a2="v2" ... am="vm"> contents </tag>
is mirrored as the Scheme expression
(tag 'a1 "v1" 'a2 "v2" ... 'am "vm" contents)
Symbols (such as a1) are used as attribute names and a string following a
symbol (such as "v1") represents an attribute value.
The contents parameter represents zero or more CDATA constituents (represented as strings) or other element instances. By use of these conventions
there is a straightforward correspondence between an HTML fragment and the LAML fragment in Scheme.
In addition to the simple mirror rules illustrated above, LAML provides for some extra flexibility. Most important, both attributes and contents parameters may occur in lists, which can be nested into each other. Such list are unfolded before further processing. This rule is very convenient because many data pieces of data (attribute lists as well as contents) tend occur in lists, when we work in a list processing language like Scheme. Also, attributes and content data may be given in arbitrary order. In addition, LAML adds white space between content constituents unless explicitly suppressed by a special marker (usually an underscore symbol). Finally, LAML handles CSS attributes in a similar way as HTML attributes, via use of a 'css:' prefix. With these additional rules, the LAML expression
(p "The numbers" (list "2" "4" "6" "8") "are all" (b "even") _ "." attribute-list)
generates the following HTML clause
<p class = "simple" style = "background-color: yellow;"> The numbers 2 4 6 8 are all <b>even</b>.</p>
provided that the Scheme variable attribute-list has the value
(class "simple" css:background-color "yellow")
The LAML system guaranties that valid HTML documents are produced. The validation is carried out by predicates on an element by element basis. Most of the predicates are automatically synthesized from the document type definitions of HTML. The more complicated validation predicates are made by manual work, however. 15 such predicates are written for HTML4.01 transitional, and 4 are made for XHTML1.0 strict. In the XHTML mirror, 5 additional predicates implement the 'element prohibition rules' which cannot be expressed in an XML DTD (cf. appendix B of the XHTML1.0 specification [27]). In case of validation problems LAML will issue a warning (or - if the author wants it - the processing can be terminated.)
An HTML mirror function in LAML generates an internal Scheme structure, similar to an abstract syntax tree. Such a structure can be rendered as a text string. In the examples above, we have shown the textual renderings rather than the abstract syntax trees. The rendering is done in a way that avoids excessive string concatenation, the use of which would cause heavy garbage collection in Scheme. During the rendering process all CDATA characters are transliterated by means of a HTML character transformation table. This allows for systematic conversion of characters to the HTML character entities. Of particular interest, we transliterate '<' and '>' to their similar character entities. Without this conversion we would not be able to trust the automatically performed document validation of LAML.
<html>
<head> <title> Quiz Example </title> </head>
<body>
<font color="#ff0000"> <b> What is LAML? </b> </font>
<br>
<input type="CHECKBOX" value="true" name="a-1-1">
A markup language in the <em> SGML family</em>.
<br>
<input type="CHECKBOX" value="true" name="a-1-2">
A set of <em> Scheme libraries </em> for textual markup purposes.
<br>
<input type="CHECKBOX" value="true" name="a-1-3">
A <em> Lisp abstracted markup language</em>.
</body>
</html>
(html
(head (title "Quiz Example"))
(body
(font 'color "#ff0000" (b "What is LAML?"))
(br)
(input 'type "CHECKBOX" 'value "true" 'name "a-1-1")
"A markup language in the" (em "SGML family")_"."
(br)
(input 'type "CHECKBOX" 'value "true" 'name "a-1-2")
"A set of" (em "Scheme libraries") "for textual markup purposes."
(br)
(input 'type "CHECKBOX" 'value "true" 'name "a-1-3")
"A" (em "Lisp abstracted markup language") _ "."
)
) |
Figure 6 shows an example of two identical documents in HTML 4.01 (transitional) and LAML There is only little gained by writing an LAML program, like the fragment in figure 6 instead of the HTML document shown above it. However, the LAML document can easily be abstracted to a higher and more pleasant level for the author. In order to provide for this, the author can use one of the predefined LAML document styles, or the author can write the necessary Scheme functions himself or herself. Figure 7 below shows a possible abstraction, which is a simple variant of the expression shown in figure 3. Notice that both the quiz machinery and the surrounding HTML 'envelope' have been abstracted.
(quiz
(quiz-entry
(question-formulation "What is LAML?")
(answers
(list
(simple-answer
"A markup language in the SGML family")
(simple-answer
"A set of Scheme libraries for textual markup purposes")
(simple-answer
"A Lisp abstracted markup language")))))
|
One of the most problematic concerns, raised by people who have used LAML, is the need for passing many relatively small strings to Scheme functions. Let us illustrate the problem with the following fragment
(p "A Lisp abstracted markup language")
in which we want to emphasize the substring Lisp in an em element:
(p "A" (em "Lisp") "abstracted markup language")
This corresponds to the following HTML fragment:
<p>A <em>Lisp</em> abstracted markup language</p>
The LAML solution involves splitting the string "A Lisp abstracted markup language" in three parts.
The middle part is to be embedded in the em function (the mirror of the em HTML element). It is
awkward and error prone to carry out the splitting and the embedding manually. Our solution is to provide an editor
command which works on a selected substring, such as "Lisp". Given the selection, the
embed editor command splits the string and it embeds the selected substring in the em function.
There is, of course, also an editor command which implements the inverse operation (unnesting and string splicing). Furthermore there are editor commands that splits and joins strings, respectively.
It may be argued that a document with many small strings passed to HTML mirror functions is hard to read. However, the total amount of markup using LAML is smaller than the markup overhead in HTML, mainly due to the use of end tags in HTML (compare the upper and lower parts of figure 6). Moreover, the clutter introduced by the string splitting is far away from the inherent clutter found in many server side programs that make use of a mixed notion of markup and program fragments. In our opinion, it is a matter of taste which of the formats to prefer.
Besides the HTML mirror, the LAML software package consists of a number of document styles and tools. An LAML document style defines a Scheme-based language for a particular purpose. The most important document styles in the LAML system are the LENO lecture note style for teaching materials [16] , the course home page style, and the manual style (for producing manual pages of Scheme libraries). Some of the educational document styles are described in a separate paper [14].
A LAML tool is a facility that processes a program or a document in a particular way. The SchemeDoc tool is able to extract documentation comments from a Scheme source file, and to pipe these through the manual document style for production of library documentation. The Scheme Elucidator tool [15 , 22] supports program explanation, similar to the style of literate programming [9] . LAML also supports XML/HTML/Scheme parsers and pretty printers.
There is a strong connection between LAML and the Emacs text editor. Emacs can help the LAML user in several ways.
One of the most important elements of the Emacs support is single key document processing. Via
single key processing, we can save and execute a LAML document by hitting a single key.
The program execution usually generates an underlying set of HTML files. In the simple case, the
processing of the file f.laml derives the file f.html. The other kinds of Emacs functionality is
template support of often used fragments, and the important embed, unembed, split, and unsplit editor commands
discussed above.
The work described in this paper is strongly connected to the Scheme programming language. Because of its power and relative simplicity, Scheme has been used in several different contexts for WWW related work.
Latte is mixture of the Latex text formatting system and Scheme, at least at the conceptual level [3]. In Latte, the author uses a Latex-like markup style. Most interesting, however, Latte mirrors a language similar to Scheme in the markup framework. This means that it is possible to make programmatic contributions to a Latte document by writing Scheme definitions in a Latex syntax.
BRL allows the WWW author to activate Scheme in designated places of a document [10]. The places are identified with square brackets. The Scheme program fragments within the square brackets are executed on the WWW server, using a slightly non-standard Scheme semantics. Thus, a BRL document is a mix of HTML markup and Scheme program fragments. BRL is particularly strong with respect to access of a relational database on the server side. Also of interest for this paper, BRL has a solution to the 'string parameter passing problem' discussed in section 5 of this paper. In BRL you can write
(brl-function ] text with <em> HTML </em> markup [brl-stuff] more free text[)
As it can be seen, free 'HTML text' appears to be embedded in ']' ... '[' quotes. As an alternative understanding, BRL details are surrounded by '[' ...']' quotes. It is a matter of taste and experience if you like this particular notation. As already discussed we have gone for a solution that avoids the mixing of HTML markup and programmatic expressions in our work.
Scheme has been used in other WWW contexts as well. Queinnec demonstrates that continuations, which represents one of the more advanced concepts in Scheme, can be used by a programmatic author to form trails through a material [23 , 24] . Queinnec uses the LAML libraries as part of his work.
Others in the functional programming community have also reflected an interest to make a bridge between functional programming and WWW authoring. Wallace and Runciman discuss two different approaches to writing and manipulating XML applications in Haskell [26]. Meijer and colleagues have in a number of papers dealt with aspects of web programming using Haskell [11]. Thiemann describes another modelling of HTML in Haskell [25]. One of the main interests of the Haskell work cited above is document validation by means of static type checking at the Haskell level. This is a contrast to our work on LAML which is based on dynamic (run time) document validation.
There is a very large body of interesting literature on the programming challenges at the WWW server side. Only a fraction of this literature is related to Lisp and Scheme [4 , 5 , 10 , 23 , 24 , 8]. When we narrow the field to the relative static documents, which we classified as generated documents in figure 1, we are not aware of more similar work than already mentioned above.
In this paper we have advocated a radical approach to WWW authoring. It is called a programmatic approach because it is based on the idea of representing a document source as a program, written in a programming language. The program execution processes the document, hereby typically deriving an equivalent HTML document, or a set of HTML documents.
We have reported on our experience with the use of Scheme for programmatic WWW authoring. During the last four years the author has written almost all his WWW material using LAML and Scheme. Substantial educational materials have been made using LAML and LAML-based document styles and tools [17 , 18]. Others have also adopted the approach, as reported in [23], but the ideas are not yet in widespread use.
We have found that Scheme and Lisp languages in general, are very good for our purposes. As demonstrated in section 5 of this paper, we have been able to approach the conventional HTML/XML means of expression in Scheme syntax. At a more general level we have found that the functional programming paradigm is well-suited for documents with nested markup elements, and for the needs of transformation between a high-level document syntax and a lower level HTML representation.
Scheme is a very flexible language, and quite popular in introductory programming courses around the world. But Scheme does not in all respects represent state of the art of functional programming. Many functional programmers would probably prefer Haskell [7] or ML [6] instead. In our opinion, use of Haskell or ML would almost certainly imply focus on type systems, static type checking, and early document validation. These are indeed important issues, and it is worthwhile to do research on the possible mix between type checking issues and the area of programmatic authoring. However, based on the LAML experience with several thousand lines of document source programs in Scheme we have only rarely felt the need for a static type checks of the documents. We rely on type checking at run time (document generation time) which often is programmed explicitly in order to give good and domain specific error messages.
We have argued that traditional imperative languages are problematic for programmatic WWW authoring, mainly because they do not fit well with nested markup elements. This observation extends to server side use of the imperative paradigm as well.
The chief advantages of the programmatic authoring approach are
The most important limiting factor for the success of programmatic authoring is that the author needs programming skills, and even more important, that the author is motivated to deal with programmatic problem solving in favor of 'easy to use' and visually oriented development tools.
LAML is available as free software from the LAML home page [19] .
In this appendix we show the demo-quiz LAML style, which is applied in the
document source program of figure 3. The demo quiz uses the validating HTML4.01 mirror.
; LAML Library loading
(lib-load "file-read.scm")
(lib-load "html4.01-transitional-validating/basis.scm")
(lib-load "html4.01-transitional-validating/surface.scm")
(lib-load "html4.01-transitional-validating/convenience.scm")
(lib-load "time.scm")
(lib-load "color.scm")
; Return a function which tags some information with tag-symbol
(define (tag-information tag-symbol)
(lambda information (cons tag-symbol information)))
; Tag function generation
(define quiz-entry (tag-information 'quiz-entry))
(define question-formulation (tag-information 'question-formulation))
(define answers (tag-information 'answers))
(define answer (tag-information 'answer))
(define answer-formulation (tag-information 'answer-formulation))
(define answer-correctness (tag-information 'answer-correctness))
(define answer-clarification (tag-information 'answer-clarification))
;;; Quiz entry selectors
(define question-of-entry (make-selector-function 2))
(define answers-of-entry (make-selector-function 3))
;;; Question selector
(define formulation-of-question (make-selector-function 2))
;;; Answer list selector
(define answer-list-of-answers (make-selector-function 2))
;;; Answer selectors
(define answer-formulation-of
(compose second (make-selector-function 2)))
(define answer-correctness-of
(compose second (make-selector-function 3)))
(define answer-clarification-of
(compose second (make-selector-function 4)))
; Form the outer structure of a HTML page
(define (html-page ttl body-form)
(html
(head (title ttl))
(body
body-form)))
; Render and write the quiz list q-lst to a HTML file.
(define (quiz q-lst)
(let ((n (length q-lst)))
(write-html '(raw prolog)
(html-page
"Quiz Example"
(con
(map present-quiz-entry q-lst (number-interval 1 n))
(p))))))
; Present a single quiz entry qe, which is assigned to the number n.
(define (present-quiz-entry qe n)
(let* ((question
(formulation-of-question (question-of-entry qe)))
(answers
(answer-list-of-answers (answers-of-entry qe)))
(m (length answers)))
(con (font-color red (b question)) (br)
(map
(lambda (a m) (present-answer a n m))
answers (number-interval 1 m))
(br))))
; Present a single answer a in quiz entry n.
; This answer is assigned to the number m.
(define (present-answer a n m)
(let ((formulation (answer-formulation-of a))
(answer-id (make-id n m)))
(con (checkbox answer-id #f)
(horizontal-space 1)
formulation (br))))
; Make an internal answer identification string based on two numbers.
(define (make-id n m)
(string-append "a" "-" (as-string n) "-" (as-string m)))
; Has quiz-entry only correct or incorrect answering possibilities
(define (black-or-white-quiz-entry? quiz-entry)
(let ((answer-list
(answer-list-of-answers (answers-of-entry quiz-entry)))
(partial-correct-answer?
(lambda (answer)
(let ((n (answer-correctness-of answer)))
(and (> n 0) (< n 100)))))
)
(null?
(filter partial-correct-answer? answer-list))))
; Make a quiz entry from a list lst
(define (make-quiz-entry-from-list lst)
(let* ((question (first lst))
(a-lst (second lst)))
(quiz-entry
(question-formulation question)
(answers (map make-answer-from-list a-lst)))))
; Make an answer entry from a list lst
(define (make-answer-from-list lst)
(let ((fo (first lst))
(co (second lst))
(cl (third lst)))
(answer
(answer-formulation fo)
(answer-correctness co)
(answer-clarification cl))))